
Na czym polega monitoring bezpieczeństwa i detekcja zagrożeń w SOC?
Czym jest monitoring bezpieczeństwa IT?
Zamiast biernie czekać na problemy, monitoring bezpieczeństwa infrastruktury pozwala aktywnie śledzić zdarzenia i kompleksowo analizować dane i przewidywać oraz eliminować zagrożenia. Chodzi przede wszystkim o to, by wyłapać anomalie i inne poszlaki świadczące o potencjalnym zagrożeniu, które mogłyby zaburzyć ciągłość działania biznesu. Taki nadzór jest kluczowym elementem nowoczesnego cyberbezpieczeństwa, ponieważ pozwala reagować na zagrożenia i zapobiegać incydentom.
Skuteczny parasol ochronny musi obejmować całą infrastrukturę organizacji, eliminując tzw. martwe pola (blind spots). Monitorowaniu powinny podlegać wszystkie newralgiczne obszary, w tym:
- Punkty końcowe (endpoints): laptopy, stacje robocze i urządzenia mobilne.
- Infrastruktura sieciowa i urządzenia bezpieczeństwa: routery, przełączniki oraz firewalle i systemy IDS/IPS.
- Środowiska chmurowe: zasoby w chmurze publicznej, prywatnej i hybrydowej.
- Systemy OT i IoT: automatyka przemysłowa oraz Internet Rzeczy.
- Warstwa serwerowa i aplikacyjna: systemy operacyjne, bazy danych oraz kluczowe aplikacje biznesowe.

Skuteczność monitoringu zależy od zapewnienia dostępu do danych z wielu źródeł (telemetrii), m.in. z urządzeń końcowych (EDR), urządzeń sieciowych (firrewalle, IDS czy IPS) czy telemetrię z chmury i aplikacji. Pozwala to uzyskać kontekst do skutecznej ochrony infrastruktury i reakcji na zagrożenia zgodnie z normami i standardami.
Dlaczego ciągły monitoring bezpieczeństwa jest ważny dla firmy?
Aby skutecznie chronić zasoby firmy i wyprzedzać ataki, niezbędny jest ciągły monitoring bezpieczeństwa. Monitoring SOC jest też ważnym elementem strategii zarządzania ryzykiem. Jego wdrożenie podnosi odporność organizacji na cyberzagrożenia, zapewniając szybką identyfikację i neutralizację incydentów w czasie rzeczywistym, co przekłada się na konkretne korzyści biznesowe:
- Minimalizacja strat finansowych – szybsze wykrycie intruza (krótszy czas Dwell Time) drastycznie obniża koszty obsługi incydentu.
- Ochrona danych i uniknięcie kar regulacyjnych (np. za naruszenie DORA czy NIS2).
- Zabezpieczenie reputacji i zaufania klientów, które trudno odbudować po wycieku.
Gwarantuje to ciągłość działania krytycznych systemów i stabilność procesów biznesowych. Warto też pamiętać, że ciągły monitoring jest wymogiem prawnym dla wielu podmiotów. Wymagają tego przepisy, takie jak dyrektywa NIS 2 oraz implementującą ją Ustawa o Krajowym Systemie Cyberbezpieczeństwa. Spełnienie tych norm pozwala uniknąć konsekwencji prawnych. Jako manager zespołu SOC, który na co dzień zajmuje się monitoringiem bezpieczeństwa, widzę tu jednak coś więcej niż tylko formalność. To realna szansa na uporządkowanie chaosu w procedurach, co w praktyce drastycznie skraca czas reakcji na incydent i buduje faktyczną odporność organizacji. Inwestycja w bezpieczeństwo IT bezpośrednio wpływa więc na ochronę przed atakami i zapobieganie potencjalnych strat finansowych i wizerunkowych.
Na czym polega proces monitoringu i detekcji zagrożeń w SOC?
W ramach Security Operations Center (SOC) monitoring i detekcja zagrożeń przebiegają według zorganizowanej, wieloetapowej procedury, która zapewnia ciągły nadzór nad bezpieczeństwem organizacji. Polega ona na gromadzeniu informacji z wielu źródeł, ich zaawansowanej analizie oraz korelacji w celu identyfikacji anomalii. Analitycy poszukują wzorców wskazujących na potencjalne incydenty. Nowoczesne narzędzia przekształcają ten proces w narzędzie do szybkiej reakcji. Budując od podstaw struktury Security Operations Center, zauważyłem, że kluczem nie jest samo posiadanie narzędzi, ale ich dostosowanie (m.in. reguły korelacyjne), zapewnienie odpowiedniej jakości danych telemetrycznych i zapewnienie jasnych procesów i standardów reakcji. To właśnie zdefiniowane procesy operacyjne – a nie tylko technologia – decydują o tym, czy analityk w porę dostrzeże zagrożenie w gąszczu logów. Można pomyśleć o SOC jak o centrum kontroli lotów dla firmowej infrastruktury – analitycy nieustannie obserwują cyfrowe radary, by upewnić się, że żaden nieautoryzowany obiekt nie wleci w chronioną przestrzeń.
POBIERZ PRZEWODNIK PO EFEKTYWNYM SECURITY OPERATIONS CENTER
Koncepcja SOC, który zbiera wybrane dane i działają tylko w oparciu o domyślne reguły i playbooki dostawców to relikt przeszłości. Dowiedz się co sprawia, że SOC działa skutecznie.

Jakie dane są zbierane i analizowane?
Dane do monitoringu pochodzą z całej infrastruktury IT, obejmując serwery, stacje robocze, systemy operacyjne oraz chmurowe, infrastrukturę OT czy IoT i środowisko aplikacjyjne. Analitycy badają przede wszystkim logi systemowe i ruch sieciowy. Analizują też dane o przepływie, takie jak NetFlow i IPFIX, aby zrozumieć wzorce komunikacji. Proces uzupełniają informacje z urządzeń bezpieczeństwa, np. firewalli i systemów IDS/IPS, dzięki czemu łatwiej wyłapać anomalie i zagrożenia.
Jaką rolę odgrywa analiza logów systemowych?
Analiza logów systemowych stanowi serce procesu detekcji. Zapewnia szczegółową kontrolę nad zdarzeniami w systemach informatycznych. Polega na badaniu zapisów aktywności z punktów końcowych czy sieci. Chodzi o to, by wykryć zagrożenia, anomalie czy podatności zanim przerodzą się w poważne zagrożenia. Kluczową rolę odgrywają tu systemy SIEM (Security Information and Event Management). Działają one jako centralny punkt agregacji, normalizacji i korelacji danych z różnych środowisk – od chmury, przez sieć, aż po endpointy. Taka integracja uzupełnia rozwiązania EDR czy NDR, które skupiają się na konkretnych warstwach środowiska jak endpointy czy sieć i daje analitykom pełny kontekst zdarzenia, dostarczając informacji niezbędnych do podjęcia szybkich i skutecznych działań.

Jaką rolę w procesie detekcji odgrywa inżynieria detekcji?
Bez inżynierii detekcji analitycy utonęliby w morzu danych. To ona jest fundamentem skutecznego SOC – odpowiada za tworzenie, optymalizację i utrzymanie reguł, które przekształcają surowe dane w precyzyjne informacje o potencjalnych zagrożeniach. Inżynier buduje i dostosowuje zaawansowane reguły w systemach SIEM do środowisk klientów. Pozwala to skutecznie identyfikować zarówno znane, jak i nowe zagrożenia. To kluczowy element poprawy skuteczności SOC, ponieważ pozwala walczyć z tzw. alert fatigue (zmęczeniem alertami) poprzez precyzyjne dostrajanie reguł, które eliminują fałszywe pozytywy (false positives) i pozwalają analitykom skupić się na realnych incydentach. Podczas wdrażania systemów klasy SIEM w firmie Atman, wielokrotnie przekonałem się, że ciągła 'inżynieria’ jest warunkiem koniecznym do utrzymania wysokiej sprawności operacyjnej. Nadmiar fałszywych alarmów to prosty przepis na przeoczenie prawdziwego ataku, dlatego optymalizacja reguł była dla nas zawsze absolutnym priorytetem.
Inżynieria detekcji sięga także po uczenie maszynowe i sztuczną inteligencję, co ułatwia analizę zagrożeń i wykrywanie anomalii. Żeby system nadążał za zmianami, specjaliści stale analizują nowe wektory ataków. Integrują też wiedzę z zakresu zarządzania podatnościami, dzięki czemu systemy reagują na dynamicznie zmieniające się cyberzagrożenia.
Jakie zagrożenia i anomalie wykrywa monitoring bezpieczeństwa?
Skuteczny monitoring bezpieczeństwa pozwala wykrywać szerokie spektrum ataków i anomalii. Obejmuje ono znane cyberataki oraz subtelne odchylenia od normy. Zaawansowane mechanizmy identyfikują multi-sekwencyjne ataki czy próby wykorzystania luk w systemach. Detekcja opiera się na analizie nietypowych wzorców, takich jak nietypowe zachowania użytkowników czy anomalie w ruchu sieciowym. Dzięki temu zespół otrzymuje dowody niezbędne do podjęcia natychmiastowych działań. Systemy te reagują zarówno na niebezpieczeństwa zewnętrzne, jak i te powstające wewnątrz organizacji.
Jak wykrywane są ataki typu phishing i malware?
Aby wykryć phishing, systemy bezpieczeństwa skanują pocztę elektroniczną w poszukiwaniu podejrzanych linków, załączników i wzorców w treści. Złośliwe oprogramowanie (malware) często zdradza swoją obecność przez analizę ruchu sieciowego – na przykład komunikację z serwerami C2 (Command and Control) czy nietypowe transfery danych. W wykrywaniu pomagają systemy antywirusowe, IDS/IPS oraz analiza behawioralna, która wykrywa anomalie w działaniu użytkowników. Nowoczesne metody, jak uczenie maszynowe, automatyzują ten proces i zwiększają skuteczność ochrony.

Jak identyfikowane są zagrożenia wewnętrzne?
Zagrożenia wewnętrzne można zidentyfikować, monitorując aktywność użytkowników i analizując logi systemowe. Kluczowe jest śledzenie dostępu do danych oraz zarządzanie uprawnieniami. Wskaźnikami zagrożenia mogą być anomalie, takie jak logowanie o nietypowych porach czy masowe pobieranie plików. Pozwala to chronić firmę przed wyciekiem danych. Detekcja obejmuje zarówno błędy ludzkie, jak i celowe szkodliwe działania.
Jak przebiega proces reagowania na incydenty bezpieczeństwa?
Gdy dojdzie do incydentu, proces reagowania musi przebiegać według z góry ustalonego planu działania, opartego na uznanych standardach, takich jak NIST SP 800-61. Jego celem jest szybka neutralizacja ataku, minimalizacja szkód i przywrócenie ciągłości działania. Po wykryciu zagrożenia zespół podejmuje kolejne kroki:
- Analiza i weryfikacja: Zespół Security Operations Center (zazwyczaj pierwsza linia wsparcia – L1) otrzymuje alert. Następnie szybko go analizuje, by potwierdzić, czy zdarzenie jest realnym incydentem.
- Ograniczenie skutków: W przypadku potwierdzenia zagrożenia, sprawa często trafia do L2, a zespół natychmiast izoluje zainfekowane systemy, odcinając je od sieci, aby powstrzymać rozprzestrzenianie się zagrożenia.
- Mitygacja i naprawa: Zespół usuwa przyczynę incydentu i naprawia wyrządzone szkody.
- Analiza post-incydent: Równolegle eksperci prowadzą dogłębną analizę. Pomaga ona zrozumieć wektor ataku i jego wpływ na organizację.
- Przywracanie i wzmacnianie: Po opanowaniu sytuacji wewnętrzny zespół lub zewnętrzny zespół (jak Trecom NOC) przywraca systemy do normalnego funkcjonowania. Zespół wzmacnia zabezpieczenia, by zapobiec podobnym zdarzeniom w przyszłości.
W samej reakcji pomagają również systemy do automatyzacji, na przykład za pomocą platform SOAR. Przyspiesza to czas reakcji. Zespół dokumentuje cały proces, co służy do audytu bezpieczeństwa i doskonalenia strategii cyberochrony. Wiele nowych platform posiada również systemy wspierane sztuczną inteligencją, która zapewnia zaawansowane sugestie reakcji.

Jakie narzędzia i technologie wspierają monitoring bezpieczeństwa?
Skuteczny monitoring bezpieczeństwa opiera się na zaawansowanych technologiach, które automatyzują procesy detekcji i reagowania na incydenty. Współczesny stos technologiczny wymaga spójnego zestawu narzędzi, które coraz częściej wykorzystują uczenie maszynowe i sztuczną inteligencję, a do najważniejszych z nich należą:
Czym są systemy SIEM i SOAR?
System SIEM (Security Information and Event Management) to technologia do wykrywania zagrożeń, która zbiera, agreguje i analizuje logi oraz zdarzenia bezpieczeństwa w czasie rzeczywistym. Można go porównać do centralnego układu nerwowego firmowego bezpieczeństwa, który odbiera sygnały ze wszystkich systemów. Jego głównym zadaniem jest korelacja danych i generowanie alertów dla zespołu SOC. Natomiast SOAR (Security Orchestration, Automation and Response) wspiera reagowanie na incydenty, automatyzując powtarzalne zadania i integrując narzędzia, co skraca czas reakcji Security Operations Center.
Czym są rozwiązania NDR i XDR?
Rozwiązania NDR (Network Detection & Response) koncentrują się na analizie ruchu sieciowego w czasie rzeczywistym. Wykorzystują uczenie maszynowe do wykrywania zagrożeń i anomalii, których nie widzą tradycyjne systemy. XDR (Extended Detection and Response) to natomiast rozszerzenie koncepcji EDR. Integruje dane z wielu źródeł: endpointów, sieci, chmury i tożsamości. Dzięki temu XDR oferuje pełny obraz sytuacji i scentralizowane reagowanie na incydenty w całej infrastrukturze IT.
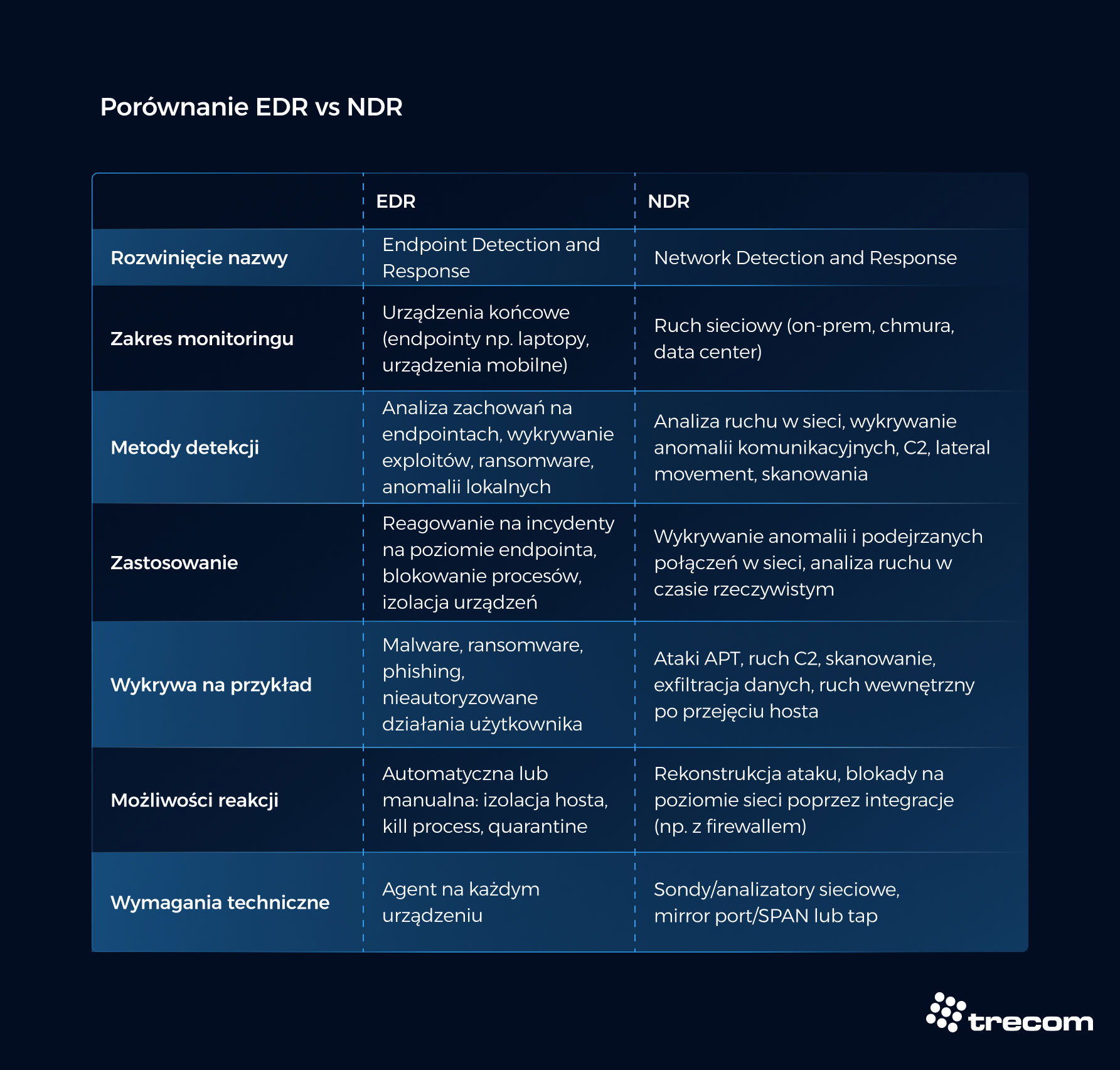
Czym różni się monitoring bezpieczeństwa od monitoringu infrastruktury IT?
Monitoring bezpieczeństwa i monitoring infrastruktury IT to dwa odrębne procesy o zupełnie innych celach. Głównym zadaniem monitoringu infrastruktury jest zapewnienie wydajności i dostępności systemów, aplikacji oraz urządzeń.
Natomiast monitoring bezpieczeństwa skupia się na ochronie przed zagrożeniami. Jego celem jest aktywne wykrywanie incydentów i anomalii m.in. poprzez analizę logów oraz ruchu sieciowego. Monitoring infrastruktury odpowiada na pytanie: „Czy systemy działają?”. Monitoring bezpieczeństwa pyta: „Czy systemy są bezpieczne?”. Choć pytania są różne, odpowiedzi często się przeplatają – nagły spadek wydajności (domena IT) może być pierwszym sygnałem ataku DDoS (domena Security). Są to procesy, które wzajemnie się uzupełniają. Wysoka dostępność systemów nie gwarantuje ich ochrony przed cyberatakami.
Czy warto zlecić monitoring bezpieczeństwa na zewnątrz?
Dla wielu firm zlecenie monitoringu bezpieczeństwa na zewnątrz okazuje się strategicznym i opłacalnym ruchem. Outsourcing zapewnia natychmiastowy dostęp do wyspecjalizowanych ekspertów i zaawansowanych narzędzi. Ich budowa i utrzymanie we własnym zakresie jest kosztowne i czasochłonne. Skorzystają na tym zwłaszcza firmy, które nie mają zasobów do stworzenia własnego Security Operations Center (SOC).
Zewnętrzny dostawca gwarantuje całodobowy nadzór i szybkie reagowanie na incydenty. Trudno to osiągnąć przy użyciu wewnętrznych zasobów. Rozwiązania takie jak Security as a Service zwiększają bezpieczeństwo i zapewniają zgodność z regulacjami (compliance). Dzięki temu nawet mniejsze organizacje zyskują poziom ochrony, który dawniej był zarezerwowany tylko dla korporacji.
Źródła
https://digital-strategy.ec.europa.eu/en/policies/nis2-directive
https://csrc.nist.gov/pubs/sp/800/61/r3/final

Michał Kaczmarek – SOC Manager z blisko 25-letnim doświadczeniem w IT, specjalizujący się w detekcji zagrożeń, zarządzaniu incydentami oraz budowie dojrzałych procesów bezpieczeństwa zgodnych z NIS2. Architekt systemów bezpieczeństwa, który rozwija zespoły SOC i wdraża rozwiązania podnoszące odporność organizacji na cyberzagrożenia w sektorze prywatnym i publicznym.

Michał Buczyński
06.05.2026


Marcin Fronczak
27.04.2026



 info@trecom.pl
info@trecom.pl +48 22 488 72 00
+48 22 488 72 00